

国产人工智能企业深度求索开发的大模型DeepSeek开源周落下帷幕。
2月28日,DeepSeek最新宣布,开源面向DeepSeek全数据访问的推进器3FS(Fire-Flyer File System)。据介绍,这是一款并行文件系统,可利用现代固态硬盘(SSD)和远程直接内存访问(RDMA)网络的全部带宽,加速和推动DeepSeek平台上所有数据访问操作。
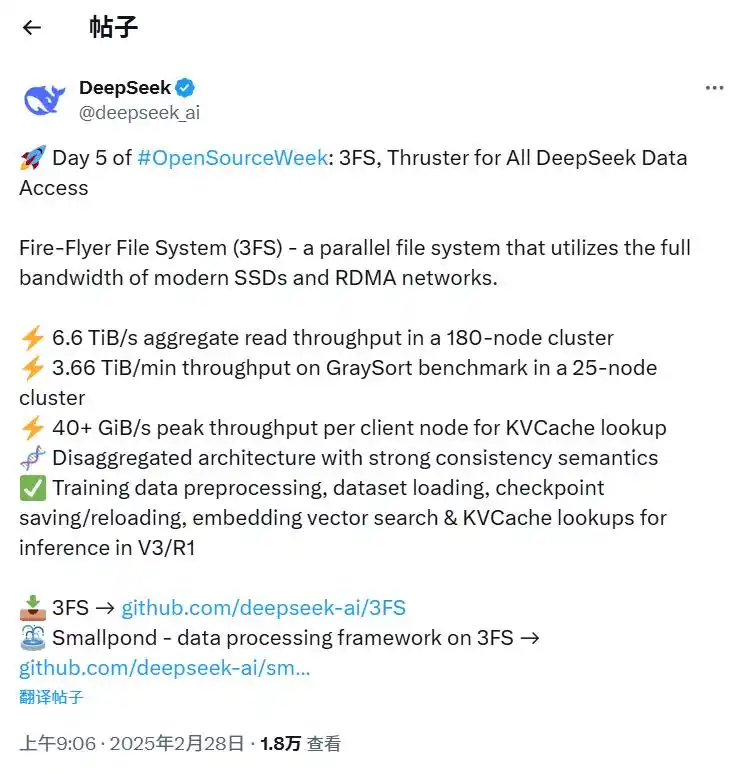
至此,DeepSeek开源周正式结束,此前2月21日午间,DeepSeek曾宣布,将开源5个代码库,以完全透明的方式与全球开发者社区分享研究进展,每日都有新内容解锁,进一步分享新的进展,并将这一计划定义为“Open Source Week”(开源周)。
“此次开源周提供的五个项目,覆盖了AI开发的核心环节——从硬件性能压榨、模型训练优化到数据处理提速,目标是让开发者开箱即用,降低技术门槛和成本,让开发者能够更高效、低成本、广泛地使用大模型。”对于开源的具体影响,华东师范大学数据科学与工程学院教授王伟告诉澎湃新闻记者,预计将拉动更多云服务提供商,降低自建云计算中心或私有化部署成本,形成更强大的生态圈,与其他大模型生态体系竞争。
他提到,DeepSeek之所以选择开源路线,不担心被同行超越,是因为其核心竞争模式和利润来源不需要依靠售卖模型服务而盈利,此外,也说明DeepSeek有相当的技术信心,“相信自己不会迅速被业内竞争对手超越,能够坚持引领最先进的技术在自身体系下持续发展。”
“此次DeepSeek的开源,从更大意义上来说,是在引导全球范围内的标准制定,形成更强的DeepSeek生态,通过开源能够吸引更多国家的开发者加入到DeepSeek生态中,将很大程度提升中国在人工智能领域的全球引领能力。”王伟认为,如果DeepSeek在全球范围内形成较强的开源生态,将会推动国内的芯片厂商进一步适配,拥有更广阔的场景和市场,实现商业闭环。
此次DeepSeek究竟开源了哪些项目,对于大模型行业有什么意义?澎湃新闻记者梳理了从2月24日至28日所有的开源项目。由于这些项目涉及众多专业术语,记者使用了DeepSeek网页版提供项目具体解释:

2月24日,首个开源的代码库为FlashMLA。
FlashMLA被称为提升显卡潜力的“加速器”,FlashMLA是DeepSeek用于Hopper GPU的高效MLA解码内核,并针对可变长度序列进行了优化,现已投入生产。
FlashMLA专门用于优化显卡(尤其是英伟达旗下GPU)的计算效率。比如,AI处理不同长度的句子(如长文本和短文本)时,它能动态分配算力,避免资源浪费,让处理速度接近硬件极限。实测显示,这让AI翻译、内容生成等任务更快、更省成本。
2月25日,DeepSeek宣布开源DeepEP,即首个用于MoE模型训练和推理的开源EP通信库。
DeepEP被称为大模型训练的“通信管家”,专门用于提升大模型训练效率设计,比如,当多个AI专家模型(MoE架构)协同工作时,它能高效协调它们之间的通信,减少延迟和资源消耗,同时支持低精度计算(如FP8),进一步节省算力。
2月26日,DeepSeek宣布开源DeepGEMM:DeepGEMM被称为矩阵计算的“省电小能手”,这是一个优化矩阵乘法(AI训练的核心计算)的工具。通过低精度计算(FP8)提升速度,再用英伟达CUDA技术修正误差,既快又准,代码仅300行,安装简单,适合快速部署。
2月27日,DeepSeek开源两个工具和一个数据集:DualPipe、EPLB 以及来自训练和推理框架的分析数据,梁文锋本人也名列开发者之中。
DualPipe主要用于解决流水线并行中的“等待时间”问题。比如,多个任务步骤速度不一时,它能双向调度,减少空闲时间。EPLB则用于自动平衡GPU负载,当某些AI专家模型任务过重时,它会复制任务到空闲显卡,避免“忙的忙死,闲的闲死”。

2月28日,DeepSeek宣布开源3FS(Fire-Flyer File System)系统:3FS被称为数据处理的“极速组合”,采用分布式文件系统,利用高速存储和网络技术(如SSD、RDMA),让数据读取速度达到每秒6.6TB,适合海量数据训练。
DeepSeek究竟为何要选择开源?此次开源将如何辐射行业?
“DeepSeek的这波开源,相当于在英伟达的AI护城河上架起了浮桥。”北京邮电大学智能交互设计专业副教授谭剑向澎湃新闻记者表示,更重要的是,DeepsSeek团队这些开源模块证明了他们有能力深入剖解英伟达CUDA和并行计算芯片的紧密耦合模式,这也是传统AI研究领域认为是不可撼动的软硬件基础设施,是英伟达宽阔的护城河。
谭剑认为,这周密集的开源模型和算法重构了AI硬件运行逻辑,不单是有力地回应了之前Deepseek训练模型仍然需要巨大算力的质疑,而且可以预见,这些核心库的开源将极大激发全球AI软硬件团队的创新活力。
对于DeepSeek对AI乃至芯片行业的影响,谭剑表示:一方面,AI模型软件研究团队可以通过算法优化(如低秩注意力压缩)降低硬件需求,另一方面,算法优化暴露了现有AI芯片的设计缺陷,我国AI芯片研发团队也可以借鉴这些算法重写设计内部计算单元和通信总线。预计未来各个细分领域都有可能用上国产的软硬件一体化AI模型,开启我国AI模型应用百舸争流的新时代。
而大模型行业资深观察者刘聪向记者表示,DeepSeek这波开源堪称“业界良心”,虽然对普通用户及大多数使用者而言,直接应用价值有限,但对底层技术从业者来说十分有用。
刘聪认为,DeepSeek将在DeepSeek-V3论文中提到的infra(基础架构)优化都提供了开源,很多开源框架都可以加上这些优化策略,随着硬件资源又一次被压缩,可能会迎来一波API(接口)降价,从而继续引领行业的公开、透明。
作为开源大模型,DeepSeek的火爆带动了开源成为如今的大模型新趋势,百度、阿里纷纷宣布旗下大模型开源,头部大厂开源似乎已成为共同选择。
香港科技大学校董会主席、美国国家工程院外籍院士沈向洋在2025全球开发者先锋大会(GDC)上表示,尽管当前闭源的份额仍然超过开源的份额,但接下来一两年将剧烈变化,平衡开源与闭源,引领未来。“大模型时代,开源并没有像以往那么多、那么快,我想,通过上海的努力,我相信开源这件事情会越做越好。中国的团队、上海的团队一定会引领开源潮流。”
“尽管在国内大模型开源似乎成为主流,但在全球范围内,这并没有形成统一。”王伟坦言,例如头部大模型厂商OpenAI依然保持闭源路线,即便是DeepSeek在开源过程中也有保留,例如在训练数据和训练过程中并未实现开源。
“开源和闭源存在路线之争,这不仅是企业之间,甚至可能上升到国家层面。在数字经济时代,信息复制成本近乎为零,DeepSeek选择开源能迅速占领市场,获得大量月活,此后可能考虑采用其他商业模式盈利,而传统的闭源大模型占领市场、推广用户需要投入大量广告成本。”
值得注意的是,人工智能的研发竞争正在愈发激烈。当地时间2月27日,大洋彼岸的人工智能巨头OpenAI发布GPT-4.5(研究预览版),并称其为公司迄今为止规模最大、性能最强的聊天模型。
不过,由于持续的高投入和高成本,GPT-4.5此次面世面临巨大争议。公开资料显示,开发者可以直接在API中调用GPT-4.5,但输入token定价比GPT-4o贵了30倍,输出token贵了15倍。OpenAI的CEO奥特曼表示,尽管想同时推出GPT-4.5Plus和Pro版本,但GPU已然用尽,下周将增加数万个GPU,然后将其推出到Plus级别。
如何看待OpenAI新推出的GPT-4.5?王伟认为,这正体现了闭源和开源两大不同发展路线,GPT-4.5在很多评测能力上有很大优势,但它耗费了巨大的算力和资金,“从我们的角度看,它虽然有优势,但需要耗费巨大的成本,我们更看好类似DeepSeek这样可持续发展的模式。”
形成对比的是,DeepSeek继续走低成本和性价比路线。2月26日,DeepSeek发布降价通知:北京时间每日00:30-08:30为错峰时段,API调用价格大幅下调,其中DeepSeek-V3降至原价的50%,DeepSeek-R1降至25%。
转载请注明来自亚星官方网-亚星开户-亚星代理,本文标题:《DeepSeek开源周这次又打开了什么魔盒?将如何影响AI开发?》










 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...