
每经编辑 杜宇
当地时间12月20日周五,在为期12个工作日的线上新品发布活动最后一日,OpenAI宣布了“压轴大作”:o1的下一代模型o3,而且一开始就要推出两个版本,一个正式的o3,还有一个相对较小的精简版o3-mini。
OpenAI的CEO Sam Altman在直播中提到,OpenAI本次12日的活动第一天官宣了上线正式版o1、所谓满血o1。活动最后一天又有o3亮相,首尾都由介绍推理模型呼应,也算是一种精心设计。
逻辑上说,o1的下一代应该命名为o2,至于为什么新模型叫o3,之前报道称,OpenAI是为了避免和名为O2的英国电信服务商冲突。Altman也确认了这点,说出于对O2的尊敬,并没有起同样的名字。
直播中,Altman称o3是“一个非常、非常聪明的模型”。OpenAi的评估结果也显示,无论在软件工程、编写代码,还是竞赛数学、掌握人类博士级别的自然科学知识能力方面,o3都明显高出o1一筹。同时测试显示,o3在OpenAI实现通用人工智能(AGI)这一奋斗目标上取得了突破,最高的测试成绩达到了类人水平。
 图片来源:视觉中国
图片来源:视觉中国今年9月,OpenAI发布o1的预览版o1 preview时称,o1是第一个具备真正通用推理能力的大模型,它的核心能力推理在测试化学、物理和生物学专业知识的基准GPQA-diamond上得到了充分体现。据OpenAI评估,o1在该测试中全面超过了人类博士专家,准确率达到78.3%,而人类专家的得分为69.7%。
在12月20日的直播中,OpenAI展示了o3的测评表现:
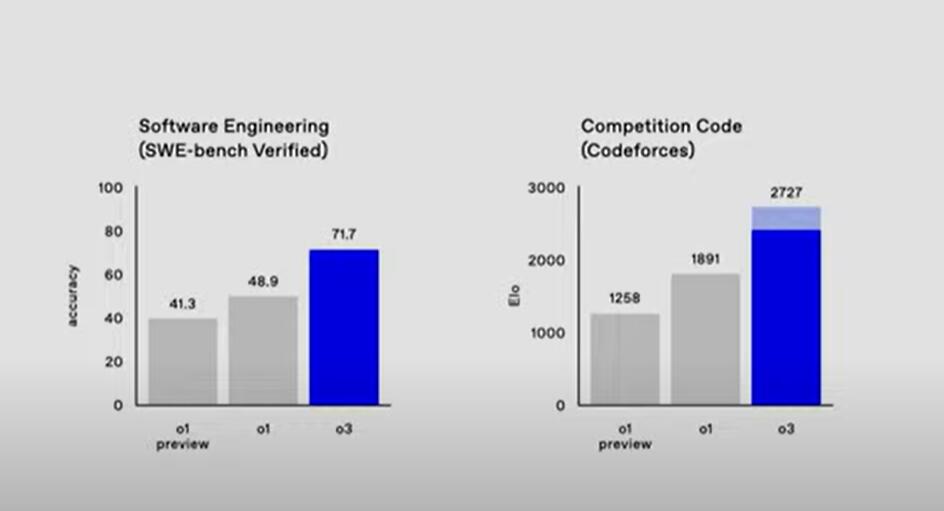
根据OpenAI8月推出的SWE-bench Verified代码生成评估基准,在软件工程的能力测评中,o3的准确度得分71.7,即准确率71.7%,远超得分48.9的o1和得分41.3的o1 preview。也就是说,o3的准确率比o1正式版高将近47%,比o1预览版高将近74%。
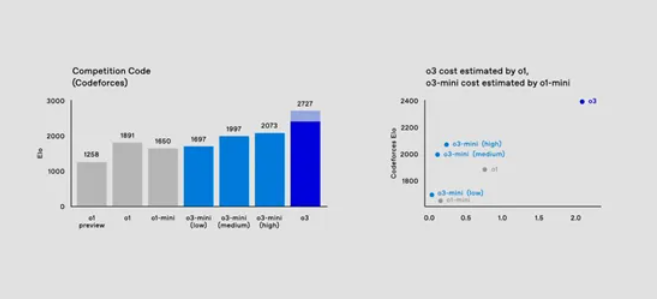
在竞争性编程网站Codeforces的竞争性代码测评中,o3取得2727的Elo评分,o1评分1891,o1 preview评分1258。这个测评结果显示,竞争性代码方面,o3的评分比o1正式版高44%,是o1预览版的两倍多。
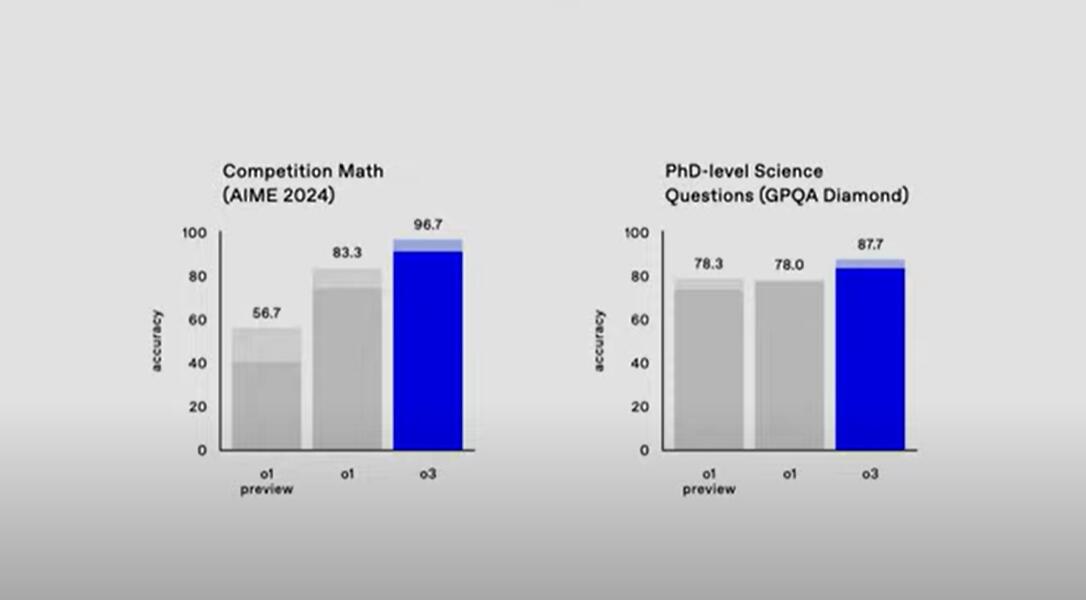
经过2024年AIME数学竞赛的题目测试,o3的准确度得分为96.7、即准确率96.7%,大幅度超过了o1预览版的56.7和o1的83.3%,仅错了一道题,相当于一名顶级数学家的水平。从竞赛数学的角度看,o3的准确率比o1正式版高15%,比o1预览版高近71%。
以人类博士专家的测试考验,在测试化学、物理和生物学专业知识的基准GPQA-diamond上,o3的准确度得分为87.7,即准确率87.7%,o1和o1 preview分别得分78.0和78.3。o3的准确率比o1高将近13%,比o1预览版高12%。
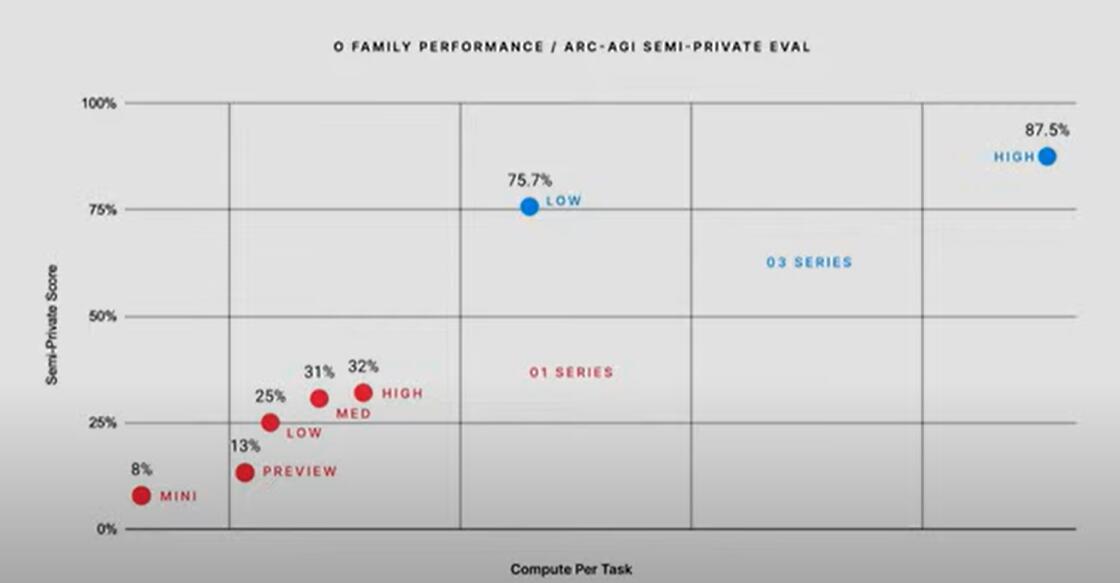
OpenAI周五还展示了,o3的推理能力已经更加接近实现AGI。
以100%为最高分的ARC-AGI评估结果显示,o1的得分在25%到32%,而o3的最低成绩为75.7%,最高成绩为87.5%。从这个结果看,o3的最佳成绩超过了标志着达到人类水平的门槛85%。
创始ARC-AGI标准的前谷歌高级工程师、AI研究员François Chollet表示,OpenAI这些推理模型在AGI测试中取得进步是“稳健的”。
Chollet周五在社交媒体X发帖,公布了同OpenAI合作进行的ARC-AGI测试结果,称“我们相信这代表了让AI适应新任务的重大突破。”
与o3模型相比,o3Mini模型在性能与成本平衡方面表现出色,能够以较低的成本提供高效的服务。
在编码评估方面,o3Mini模型展现出了出色的性能提升。在CodeForces的评估中,随着思考时间的增加,o3Mini模型的表现不断提升,逐渐超越了o1Mini模型。
在中位思考时间下,o3Mini模型的性能甚至优于o1模型,能够以大约一个数量级的更低成本提供相当甚至更好的代码性能。这意味着开发人员可以在不增加过多成本的情况下,获得更高效的编程辅助,提高开发效率,降低开发成本。
在数学能力测试中,o3Mini模型在2024年数据集上表现出色。o3Mini低模型的性能与o1Mini相当,而o3Mini中位数模型则取得了比o1更好的性能。在处理诸如GPQA等困难数据集时,o3Mini模型也能展现出一定的优势,实现了接近即时响应的效果。
此外,o3Mini模型支持函数调用、结构化输出、开发者消息等一系列功能,与O1模型相当。在实际应用中,o3Mini模型在大多数评估中实现了可比或更好的性能。
在现场演示中,o3Mini模型的强大功能得到了直观展示。例如,在一项任务中,模型被要求使用Python实现一个代码生成器和执行器。当启动运行该Python脚本后,模型成功启动了本地服务器,并生成了包含文本框的用户界面。
用户在文本框中输入编码请求后,模型能够迅速将请求发送至API,并自动解决任务,生成代码并保存至桌面,随后自动打开终端执行代码。整个过程复杂且涉及大量代码处理,但o3 Mini模型在低推理努力模式下依然表现出了极快的处理效率。

虽然o3的测评看上去表现惊艳,但OpenAI应该不会很快面向大众上线这款新的超级推理模型。
从12月20日开始,OpenAI允许安全研究人员可以注册访问o3 和 o3-mini的预览。OpenAI的一名发言人称,OpenAI计划明年初正式发布这些新的o3模型。
每日经济新闻综合公开资料










 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...